%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Audio Processing
AI ASMR
AI ASMR Generator is a tool that uses AI technology to generate ASMR videos. It helps users quickly create high-quality ASMR videos, providing a richer experience and stimulation.
AI
37.0K

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
38.4K
Unifab
UniFab is a powerful AI-powered video and audio enhancement tool. Utilizing advanced super-resolution technology, it can upscale video resolution to 8K/16K while converting SDR to HDR, providing users with a cinematic viewing experience. Its AI-driven deep learning intelligently analyzes and optimizes each frame, resulting in vibrant colors, realistic details, and clear visuals. Furthermore, UniFab supports audio upmixing, upgrading audio tracks to EAC3 5.1/DTS 7.1 surround sound, immersing users in a movie-like auditory experience. This product is primarily targeted at photographers, film and television enthusiasts, and video creators, helping them optimize video content and improve the quality of their creations.
Video Editing
67.6K
Inspiremusic
InspireMusic is an AIGC toolkit and model framework focused on music, songs, and audio generation, developed using PyTorch. It achieves high-quality music generation through audio tokenization and decoding processes, combining autoregressive transformers and conditional flow matching models. This toolkit supports multiple conditional controls such as text prompts, music styles, and structures, enabling the generation of high-quality audio at both 24kHz and 48kHz, as well as supporting long audio generation. Additionally, it offers convenient fine-tuning and inference scripts for users to adjust the model according to their needs. The open-source nature of InspireMusic aims to empower everyday users to enhance sound effects in their research through music creation.
Music Generation
59.3K
Aivocal
AIVocal is an online vocal elimination tool based on artificial intelligence technology. It can quickly remove vocals from any song to create accompaniment tracks or separate instrumental tracks, enhancing music production efficiency. This product meets the needs of music producers, content creators, and cover artists with its high efficiency, precision, and user-friendliness. AIVocal supports various audio formats such as MP3, WAV, and FLAC, making it suitable for professional music production and daily entertainment uses.
Audio Production
57.1K
Fresh Picks
Omniaudio 2.6B
OmniAudio-2.6B is a multimodal model with 2.6 billion parameters that seamlessly processes both text and audio inputs. This model combines Gemma-2B, Whisper Turbo, and a custom projection module. Unlike the traditional method of chaining ASR and LLM models, it unifies both capabilities in an efficient architecture, achieving minimal latency and resource overhead. This enables it to securely and rapidly process audio-text directly on edge devices such as smartphones, laptops, and robots.
Speech Recognition
54.4K
Comfyui MMAudio
ComfyUI-MMAudio is a plugin based on ComfyUI that allows users to process audio using the MMAudio model. The main advantage of this plugin is its ability to deliver high-quality audio generation and processing capabilities, supporting various audio models and easily integrating into existing audio processing workflows. It is developed by kijai and is open source, available on GitHub. Currently, it is primarily aimed at tech enthusiasts and audio processing professionals and is available for free.
Audio Production
83.1K
Auralis
Auralis is a text-to-speech (TTS) engine that converts text into natural speech quickly, supports voice cloning, and boasts extremely fast processing speeds—capable of handling an entire novel in just minutes. The product is distinguished by its high speed, efficiency, easy integration, and high-quality audio output, making it suitable for scenarios requiring rapid text-to-speech conversion. Built on a Python API, Auralis supports long text streaming, built-in audio enhancement, automated language detection, and more. Developed by AstraMind AI, Auralis aims to provide a practical TTS solution for real-world applications. While product pricing is not explicitly stated on the page, the codebase is released under the Apache 2.0 License, allowing for free use in projects.
Text-to-Speech
106.0K
Songcleaner
SongCleaner is a platform that utilizes artificial intelligence technology to clean inappropriate lyrics from songs. Users can upload MP3 or WAV audio files and the AI will analyze and edit them, generating cleaned versions suitable for all ages along with accompanying tracks. This technology is significant as it makes music content more appropriate for public play and family settings while maintaining the original charm of the music. SongCleaner offers a fast, free, and user-friendly solution to meet the demand for clean music content.
Audio Production
147.9K
English Picks

Suno V4
Suno v4 is a music creation platform that helps users create music faster by providing clearer audio, sharper lyrics, and more dynamic song structures. This platform not only enhances the quality of music creation but also enriches the user experience with new features and technologies, such as the ReMi lyric assistance model and personalized cover art. The backdrop of Suno v4 is the demand for more efficient and higher quality creative tools in the music creation field, which it meets through technological advancements. Currently in beta testing, Suno v4 primarily serves Pro and Premier users.
Music Production
59.9K

Hertz Dev
Hertz-dev is a full-duplex, audio-only transformer foundational model open-sourced by Standard Intelligence, featuring 8.5 billion parameters. This model represents scalable cross-modal learning technology capable of converting mono 16kHz speech into an 8Hz latent representation at a bitrate of 1kbps, outperforming other audio encoders. Key advantages of hertz-dev include low latency, high efficiency, and accessibility for researchers to fine-tune and build upon. Contextual information indicates that Standard Intelligence is committed to developing general intelligence that benefits humanity, with hertz-dev being a substantial step in that direction.
Model Training and Deployment
51.6K
Fish Agent V0.1 3B
Fish Agent V0.1 3B is a groundbreaking speech-to-speech model capable of capturing and generating environmental audio information with unprecedented accuracy. The model utilizes a non-semantic tagging architecture, eliminating the need for traditional semantic encoders/decoders. Additionally, it is a cutting-edge text-to-speech (TTS) model trained on 700,000 hours of multilingual audio content. As a continuation of the Qwen-2.5-3B-Instruct pre-trained version, it has been trained on 200 billion speech and text tags. The model supports eight languages, including English and Chinese, with approximately 300,000 hours of training data for each of these languages and around 20,000 hours for others.
Text-to-Speech
53.3K
Universal 2
Universal-2 is the latest speech recognition model launched by AssemblyAI, surpassing the previous Universal-1 in both accuracy and precision. It captures the complexities of human language more effectively, providing users with audio data that requires no secondary verification. The significance of this technology lies in its ability to deliver sharper insights, faster workflows, and an exceptional product experience. Universal-2 features notable improvements in proper noun recognition, text formatting, and alphanumeric recognition, consequently reducing word error rates in practical applications.
Speech Recognition
50.8K
Diarizen
DiariZen is a speaker segmentation toolkit powered by AudioZen and Pyannote 3.1. Speaker segmentation is a crucial step in audio processing, allowing the differentiation of various speakers within a segment of audio. This technology is widely applicable in fields such as meeting transcription, call monitoring, and security surveillance. Key advantages of DiariZen include its user-friendliness, high accuracy, and open-source nature, enabling researchers and developers to freely utilize and enhance it. DiariZen is available on GitHub under the MIT license, meaning it is completely free and can be used commercially.
Development & Tools
54.9K
AILIBRI
AILIBRI is a directory website that brings together over 2,000 AI neural network tools across various fields including text, image, video, and audio. It greatly facilitates users' search for suitable AI tools, catering to both professionals and beginners. The site offers detailed categorization and search capabilities to help users quickly find the tools they need.
AI information platform
65.1K

Seed Vc
seed-vc is a voice conversion model based on the SEED-TTS architecture, capable of zero-shot voice conversion, meaning it can convert voices without requiring specific voice samples from individuals. This technology excels in audio quality and tonal similarity, holding substantial research and application value.
AI speech synthesis
109.6K
Easy Voice Toolkit
Easy Voice Toolkit is an AI voice toolkit based on open-source voice projects, providing various automated audio tools including speech model training. The toolkit seamlessly integrates to create a complete workflow, allowing users to selectively use these tools or utilize them in sequence to gradually convert raw audio files into ideal speech models.
AI audio editing
80.3K
Fresh Picks
Audio Chat
Audio Chat is a dedicated website for processing audio files, allowing users to upload audio recordings from lectures, meetings, or interviews for dialogue analysis. Utilizing advanced audio processing technology, this product helps users quickly grasp key points of the conversation, enhancing learning and work efficiency.
Speech Recognition
55.5K
DETECT 2B
DETECT-2B is Resemble AI's latest deepfake detection solution. It can detect over 30 languages with an accuracy of over 94% within 200 milliseconds. Our efficient and multilingual technology effectively addresses audio fraud based on AI.
AI detection
76.2K
Fresh Picks
Stable Audio Open 1.0
Stable Audio Open 1.0 is an AI model that utilizes an autoencoder, T5-based text embeddings, and a transformer-based diffusion model to generate up to 47 seconds of stereo audio. It generates music and audio through text prompts, supporting research and experiments to explore the current capabilities of generative AI models. The model is trained on datasets from Freesound and the Free Music Archive (FMA), ensuring data diversity and copyright legality.
AI Music Generation
78.9K

Spleetergui
SpleeterGUI is a desktop application for music source separation. Users don't need to install Python or Spleeter as the application comes with pre-installed Python and Spleeter versions. By separating audio tracks, users can extract different sound sources from music, providing greater flexibility in audio processing.
Audio Production
84.5K
Chinese Picks
MVSEP
MVSEP is an online audio processing tool that employs advanced audio separation technology to isolate music and speech from audio files. It is suitable for fields such as music production, audio editing, broadcasting, and film post-production. Its advantages include high-quality audio output, fast processing speed, and a user-friendly interface. Different models are available for selection.
Audio Production
123.6K

Fineshare SonixTw
SonixTw AI Voice Cloning is a high-quality online artificial intelligence voice cloning product. Through a single recording, you can achieve cloning, retaining delicate emotions and tone. You can create digital twin identities for yourself and your team, fully utilize the power of your voice, and enhance your life experience and work efficiency.
AI speech recognition
135.0K
Listen411
speech-to-text transcription
49.1K
Ultimate Vocal Remover GUI
Ultimate Vocal Remover GUI is a vocal removal tool that utilizes deep neural network technology. The core developer trained all provided models except for the Demucs v3 and v4 4-channel models. This application uses advanced source separation models to remove vocals from audio files. It runs effectively without any additional prerequisites and is compatible with Windows 10 and above.
AI audio editing
73.7K
Speech To Text AI
Speech To Text - AI is an online tool that can convert user-uploaded audio files or YouTube video links into text. This application utilizes advanced AI technology to recognize and transcribe audio content, enabling users to quickly and conveniently extract textual information from audio.
Speech-to-Text Translation
118.1K
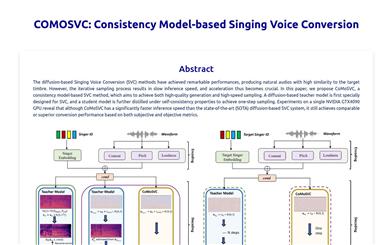
COMOSVC
COMOSVC is a singing pitch transformation technology based on consistency models that achieves high-quality transformation effects and fast sampling speed. This technology first designs a teacher model based on diffusion for the singing pitch transformation task and then uses self-consistency properties for knowledge distillation to achieve one-step sampling. Compared to the most advanced singing pitch transformation systems based on diffusion, COMOSVC maintains, and even exceeds, comparable transformation performance while significantly faster inference speed.
AI audio editing
80.0K
Devmind AI
DevMind AI seamlessly integrates the reasoning capabilities of various models, including text, image, video, audio, and code, helping you develop like a pro! DevMind AI empowers your projects with AI functionalities.
Development & Tools
51.1K
Music.ai
The Audio Intelligence Platform? is an audio intelligence platform for enterprises and developers. It provides a range of advanced Complementary AI? models for audio separation, transcription, mixing, mastering, generators, encoders, effects processing, and more. The platform boasts a user-friendly interface, powerful performance, and security safeguards, offering innovative and convenient audio solutions for your projects.
Development & Tools
58.2K
Soundify
Soundify is an AI-based audio editing tool that offers functions such as audio repair, quality enhancement, and noise reduction. It helps users easily and quickly optimize and improve audio quality. The product utilizes unique deep learning algorithms to accurately identify and eliminate noise, smooth audio details, making the voice clearer and smoother. It also provides other editing functions such as audio cutting and speed adjustment. Soundify is user-friendly and fully automatic, significantly reducing the workload of audio post-production. It is suitable for both individual users and professional audio professionals.
Audio Editing
143.2K
- 1
- 2
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.2K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
41.7K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
40.8K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M